
INNER JOIN 과 OUTER JOIN - 두 개 이상의 테이블을 조인할 때, 일치하는 값이 없는 행은 조인에서 제외된다. 이것을 INNER JOIN이라고 하며,
명시적으로 사용하지 않을 시에는 기본적으로 INNER JOIN 이다.
하지만 일치하지 않은 값 또한 JOIN에 포함 시킬 수도 있다. 이것을 OUTER JOIN이라고 하며, 반드시 OUTER JOIN임을 명시해야 한다.
꽤 중요한 문장들이 많습니다
조인 완벽 이해가능한 예제 ( 일반적인 INNER JOIN , 다중조인 )
-- 직급이 대리이면서 아시아 지역에 근무하는 직원조회 EMPLOYEE JOB LOCATION + DEPARTMENT
-- 사번, 이름 , 직급명, 부서명, 근무지역명, 급여를 조회하세요
-- (조회시에는 모든 컬럼에 테이블 별칭을 사용하는것이 좋다. )


실행 결과

여기부터여기부터여기부터여기부터여기부터여기부터여기부터여기부터여기부터여기부터여기부터여기부터여기부터
여기부터여기부터여기부터여기부터여기부터여기부터여기부터여기부터여기부터
여기부터여기부터여기부터여기부터여기부터여기부터여기부터
서브쿼리 시작 서브쿼리 시작 서브쿼리 시작 서브쿼리 시작 서브쿼리 시작 서브쿼리 시작
--@서브쿼리(SubQuery)
/*하나의 SQL 문안에 포함되어있는 또다른 SQL 문
알려지지 않은 조건에 근거한 값들을 검색하는 SELECT 문장을 작성하는데 유용함
메인쿼리가 서브쿼리를 포함하는 종속적인 관계
서브쿼리는 반드시 소괄호 로 묶어야함
-> (SELECT...) 형태*/
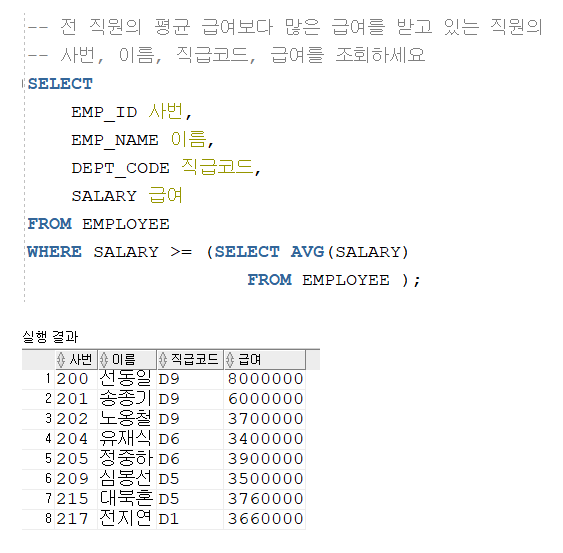
※ 전 직원의 급여 평균

ㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡ
--서브쿼리의 유형
--단일행 서브쿼리 : 서브쿼리의 조회 결과값이 1개 행일때
--다중행 서브쿼리 : 서브쿼리의 조회 결과값의 행이 여러개일때
--다중열 서브쿼리 : 서브쿼리의 조회 결과값의 컬럼이 여러개일때
--다중행 다중열 서브쿼리 : 조회경로가 행 수와 열수가 여러개일때
--상(호연)관서브쿼리 : 서브쿼리가 만든 결과값을 메인쿼리가 비교 연산할때
-- 메인쿼리의 값이 변경되면 서브쿼리의 결과값도 바뀌는 서브쿼리
--스칼라 서브쿼리 : 상관쿼리이면서 결과값이 하나인 서브쿼리
--* 서브쿼리의 유형에 따라 서브쿼리 앞에 붙은 연산자가 다름
--1. 단일행 서브쿼리
-- 단일행서브쿼리앞에는 일반비교 연산자사용
-- >,<,>=,<=,=, !=,<>,^= (서브쿼리)
--노옹철 사원의 급여보다 많이 받는 직원의
--사번, 이름 , 부서, 직급, 급여를 조회하세요

-- 가장 적은 급여를 받는 직원의
-- 사번, 이름, 직급, 부서, 급여, 입사일을 조회하세요

-- 서브쿼리는 SELECT, FROM, WHERE, HAVING, ORDER BY에도 사용 가능
-- 부서별 급여의 합계가 가장 큰 부서의 부서명, 급여 합계를 구하세요



2 단계 ( 메인 쿼리 작성 )
3 단계 : 1, 2단계 합체
다중행 서브쿼리 라서 IN 사용
메인 쿼리에서 WHERE 급여 IN 부서별 최고 급여
-- 관리자에 해당하는 직원에 대한 정보와 관리자가 아닌 직원의 정보를 추출하여 조회
-- 사번, 이름 , 부서명 , 직급명, '관리자' AS 구분 / '직원' AS 구분
풀이 방법 : 서브쿼리문 부터 천천히 해석 해야 한다.
1. (EMPLOYEE 에서 MANAGER_ID가 NULL이 아닌 중복 없이 MANAGER_ID 출력 ) = 서브쿼리 부분 ( AND EMP_ID IN 뒤 괄호 )
2. EMP_ID 와 1. (EMPLOYEE 에서 MANAGER_ID가 NULL이 아닌 중복 없이 MANAGER_ID 출력 ) 들 중 일치하는 EMP_ID 들의 사번, 이름, 부서명, 직급명, 구분을 출력하라 !!
UNION
-- ANY : 서브쿼리의 결과중에서 하나라도 참이면 참
/* > ANY : 최소값 보다 크면
>= ANY : 최소값보다 크거나 같으면
< ANY : 최대값보다 작으면
<= ANY : 최대값보다 작거나 같으면
= ANY : IN과 같은 효과
!= ANY : NOT IN과 같은 효과 */
--ALL : 서브 쿼리의 결과중에서 모두 참이면 참 (ANY 와는 약간 다른 개념 )
/* > ALL : 최대값 보다 크면
>= ALL : 최대값보다 크거나 같으면
< ALL : 최소값보다 작으면
<= ALL : 최소값보다 작거나 같으면
= ALL : SUBSELECT의 결과가 1건이면 상관없지만 여러건이면 오류가 발생
!= ALL : 위와 마찬가지로 결과가 여러건이면 오류 발생
*/
--EXISTS : 서브쿼리의 결과 중에서 만족하는 값이 하나라도 존재하면 참
-- 참, 거짓 서브쿼리안에 값이 있는지 없는지
-- 서브쿼리 결과가 참이면 메인쿼리를 실행, 서브쿼리 결과가 거짓이면 메인쿼리를 실행하지않는다.
-- 다중열 서브쿼리
--> 서브쿼리의 조회결과 컬럼의 개수가 여러개일때 (다중행하고는 다르게 결과값이 컬럼이 여러개!!)
-- 퇴사한 여직원과 같은부서, 같은 직급에 해당하는 사원의 이름 , 직급코드 ,부서코드, 입사일을 조회
SUBSTR EMP_NO = 2 주민번호 뒷자리 2 (여직원) 인거 비교
-- 상[호연]관 서브쿼리
-- 일반적으로는 서브쿼리가 만든 결과값을 메인쿼리가 비교 연산
-- 메인쿼리가 사용하는 테이블의 값을 서브쿼리가 이용해서 결과를 만듬
-- 메인쿼리의 테이블 값이 변경되면, 서브쿼리의 결과값도 바뀌게 됨
--메인쿼리에 있는것을 서브쿼리에서 가져다쓰면 상관 서브쿼리
--서브쿼리가 독단적으로 사용이 되면 일반서브쿼리
-- 스칼라 서브쿼리 = 단일행 서브쿼리 + 상관쿼리(-> 상관쿼리 이면서 결과값이 1개인 서브쿼리)
-- ( 행이 1개만 필요로하는 ) SELECT절, WHERE절, ORDER BY절 사용 가능
-- WHERE절에서 스칼라 서브쿼리 이용
-- 동일 직급의 급여 평균보다 급여를 많이 받고 있는 직원의
-- 사번, 직급코드, 급여를 조회하세요
-- 동일 직급의 급여 평균
-- 동일 직급의 급여 평균보다 급여를 많이 받고 있는 직원의
-- 사번, 직급코드, 급여를 조회하세요
--SELECT 절에서 스칼라 서브쿼리 이용
-- 모든 사원의 사번, 이름, 관리자 사번, 관리자명 조회
-- ORDER BY 절에서 스칼라 서브쿼리 이용
-- 모든 직원의 사번, 이름 , 소속 부서코드 조회
-- 단 부서명 내림차순 정렬
-- 서브쿼리의 사용 위치 :
-- SELECT절, FROM절, WHERE절, HAVING절, GROUP BY절, ORDER BY절
-- DML 구문 : INSERT문, UPDATE문
-- DDL 구문 : CREATE TABLE문, CREATE VIEW문
-- FROM 절에서 서브쿼리를 사용할 수 있다 : 테이블 대신에 사용
-- 인라인 뷰(INLINE VIEW)라고 함
-- : 서브쿼리가 만든 결과집합(RESULT SET)에 대한 출력 화면
--JOB 코드별 월급 평균(TRUNC(AVG(E2.SALARY), -5))을 구하고
--월급이 이와 일치하는 사원정보 이름, 직급명,월급 구하기
-- 부서명이 인사관리부인 사원명 , 부서명, 직급이름 을 구하시오 (인라인뷰사용)
/*우선 TOP-N 분석에 대해 알아보자
# TOP-N 분석이란?
TOP-N 질의는 columns에서 가장 큰 n개의 값 또는 가장 작은 n개의 값을 요청할 때
사용됨
예) 가장 적게 팔린 제품 10가지는? 또는 회사에서 가장 소득이 많은 사람 3명은?
*/
-- 인라인뷰를 활용한 TOP-N분석
-- ORDER BY 한 결과에 ROWNUM을 붙임
-- ROWNUM은 행 번호를 의미함 (ROWNUM 은 출력되는 SELECT 된 행마다 자동으로 순차적인 번호를 붙여주는 값)
--ex) --TOP-N 분석 : 회사에서 연봉이 가장 높은 사람 5명은?
인라인 뷰로 먼저 정렬한 뒤 ROWNUM을 붙인다.
인라인 뷰를 안 썼다면 ROWNUM이 붙여진 뒤 정렬을 하기 때문에 뒤죽박죽이 되었을 것
-- 급여 평균 3위안에드는 부서의 부서코드와 부서명 , 평균급여를 조회하세요 (인라인뷰를 활용한 TOP-N분석 사용 )
위 문제 인라인 뷰만 따로
-- RANK() OVER(정렬기준) / DENSE_RANK() OVER(정렬기준)
-- 보다 쉽게 순위 매기는 함수
-- RANK() OVER : 동일한 순위 이후의 등수를 동일한 인원 수 만큼 건너뛰고 순위 계산
-- EX) 공동 1위가 2명이면 다음 순위는 2위가 아니라 3위
-- DENSE_RANK() OVER : 동일한 순위 이후의 등수를 무조건 1씩 증가시키는
-- EX) 공동 1위가 2명이더라도 다음 순위는 2위
-- 직원 테이블에서 보너스 포함한 연봉이 높은 5명의 RANK() OVER
-- 사번, 이름, 부서명, 직급명, 입사일을 조회하세요
-- WITH 이름 AS (쿼리문)
-- 서브쿼리에 이름을 붙여주고 사용시 이름을 사용하게 됨
-- 인라인뷰로 사용될 서브쿼리에서 이용됨
-- 같은 서브쿼리가 여러번 사용될 경우 중복 작성을 줄일 수 있다.
WITH << 꼭 함수 처럼 생겼다
-- 부서별 급여 합계가 전체 급여의 총 합의 20%보다 많은
-- 부서의 부서명과, 부서별 급여 합계 조회
/*@ 데이터 딕셔너리 (Data Dictionary)
-> 자원을 효율적으로 관리하기 위한 다양한 정보를 저장하는 시스템 테이블
-> 데이터 딕셔너리는 사용자가 테이블을 생성하거나 사용자를 변경하는 등의
작업을 할 때 데이터베이스 서버에 의해 자동으로 갱신되는 테이블
-> 사용자는 데이터 딕셔너리의 내용을 직접 수정하거나 삭제할 수 없음
-> 데이터 딕셔너리 안에는 중요한 정보가 많이 있기 때문에 사용자는 이를 활용하기 위해
데이터 딕셔너리 뷰를 사용하게 됨
※ 뷰(VIEW)는 뒤에 배우겠지만 미리 말씀 드리면 원본 테이블을
커스터마이징해서 보여주는 원본테이블의 가상의 TABLE 객체
@ 3개의 데이터 딕셔너리 뷰 (Data Dictionary View)
1. DBA_XXXX : 데이터 베이스 관리자만 접근이 가능한 객체 등의 정보 조회
(DBA는 모든 접근이 가능하므로 결국 디비에 있는 모든 객체에 대한 조회가 됨)
2. ALL_XXXX : 자신의 계정이 소유하거나 권한을 부여받은 객체 등에 관한 정보 조회
3. USER_XXXX : 자신의 계정이 소유한 객체 등에 관한 정보 조회
*/
SQL에서 정해진 예약어 !!!
FROM절 연산에서 ROWNUM 이 먼저 정해지고 그다음 ORDER BY 가 수행되기 때문에 ROWNUM 순으로 정렬이 되어있지 않다 ( 4번 5번)
이렇게 수정해야 한다
FROM 에도 서브쿼리가 적용이 되는군요 !!
'더존 노션 필기 옮기기 > SQL' 카테고리의 다른 글
| MySQL 튜토리얼 (1) | 2022.12.07 |
|---|---|
| Oracle EMPLOYEE DDL DML (0) | 2022.11.22 |
| SQL 2일차 오라클 DB 2 단일행함수 , 그룹함수 (0) | 2022.08.30 |
| SQL 1일차 오라클DB 설치 및 설정 (0) | 2022.08.30 |