SELECT
리터럴 ( 큰따옴표 : 컬럼에 별칭 , 작은 따옴표 : 데이터로 사용가능)
DISTINCT
비교 연산자
연산자 설명
= 같다
>,< 크다/작다
>=,=< 크거나 같다/작거나 같다
<>,!=,^= 같지 않다
BETWEEN AND 특정 범위에 포함되는지 비교
LIKE / NOT LIKE 문자 패턴 비교
★★★★★★★
LIKE 연산자: 문자 패턴이 일치하는 값을 조회 할때 사용
--컬럼명 LIKE '문자패턴'
--문자패턴 : '글자%'(글자로 시작하는 값)
-- '%글자%'(글자가 포함된 값)
-- '%글자'(글자로 끝나는 값)
'%' 와 '_' 와일드 카드 로 사용할수있다
와일드 카드 : 아무거나 대체해서 사용할수 있는 것
_: 한문자
%:모든것
--EMPLOYEE 테이블에서 _앞글자가 3자리인 이메일 주소를 가진 사원의
--사번, 이름, 이메일 주소를 조회
--ESCAPE
--LIKE '%[문자][실제문자로인식시킬문자]%' ESCAPE '[문자]
-- _ << 이 키워드를 문자로 인식시키기 위해서 임의로 특수문자 (#)을 지정했다.
-- # 뒤에있는 키워드는 글자로 처리해주세요~ 라는 뜻 .
SELECT EMP_ID, EMP_NAME, EMAIL
FROM EMPLOYEE
WHERE EMAIL LIKE '___#_%' ESCAPE '#';
IS NULL / IS NOT NULL NULL 여부 비교
IN / NOT IN 비교 값 목록에 포함/미포함 되는지 여부 비교
ㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡ
함수를 사용할수 있는 위치 : SELECT 절, WHERE 절, GROUP BY 절, HAVING절, ORDER BY 절
★★★★★
INSTR = 문자열 속에서 문자/문자열 찾기 리턴 값 = 좌표 (숫자)
INSTR('문자열' | 컬럼명,'문자', 찾을 위치의 시작값 ,[빈도])
파라미터 설명
STRING 문자 타입 컬럼 또는 문자열
STR 찾으려는 문자(열)
POSITION 찾을 위치 시작 값 (기본값 1)
(양수) POSITION > 0 : STRING의 시작부터 끝 방향으로 찾음
(음수) POSITION < 0 : STRING의 끝부터 시작 방향으로 찾음
OCCURRENCE 검색된 STR의 순번(기본값 1), 음수 사용 불가
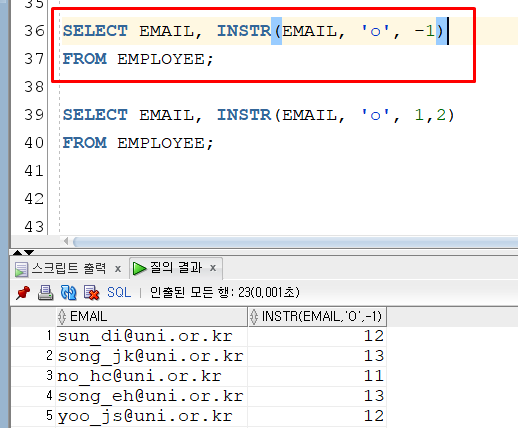
뒤에서 부터 'o' 를 찾는다. (마지막 파라미터 기본값이 1이므로 제일 처음 나오는 'o' 의 인덱스를 리턴 한다. )
INSTR(EMAIL, 'O', -1 , 1 ) 인셈
뒤에서 찾긴 하지만 인덱스를 세는건 앞에서부터 센다.

앞에서 부터 두 번째로 나오는 'o' 의 인덱스를 리턴 한다.
LTRIM , RTRIM , TRIM

★★★★★★
SUBSTR
--SUBSTR: 컬럼이나 문자열에서 지정한 위치로 부터 지정한 문자열을 잘라서 리턴하는 함수
리턴 값 : 문자열
--SUBSTR('문자열', 시작 위치, 자를 길이)

출력 결과
THEMONEY
THE
--LOWER/UPPER/INITCAP : 대소문자 변경해주는 함수
--LOWER(문자열| 컬럼) : 소문자로 변경해주는 함수
--CONCAT : 문자열 혹은 컬럼두개를 입력받아 하나로 합친후 리턴

-- REPLACE : 컬럼혹은 문자열을 입력받아 변경하고자 하는 문자열을 변경

-- 숫자 처리 함수 : ABS, MOD, ROUND, FLOOR, TRUNC , CEIL
-- ABS(숫자 | 숫자 로 된 컬럼명 ) :절대값 구하는 함수
-- MOD(숫자 | 숫자로된 컬럼명, 숫자 | 숫자로된컬럼명) : 두 수를 나누어서 나머지를 구하는 함수
-- 첫 인자는 나누어지는 수, 두 번째 인자는 나눌 수
-- ROUND( 숫자 | 숫자로된 컬럼명, [위치]) : 반올림해서 리턴하는 함수
-- 소수점의 첫 번째 자리가 0번 인덱스다. -1 은 정수 첫 번째 자리이다.
-- FLOOR(숫자 | 숫자로된 컬럼명)
--: 내림처리 하는 함수 (인자로 전달받은 숫자 혹은 컬럼의 소수점 자리수를 버리는 함수)
-- TRUNC(숫자 | 숫자로된 컬럼명 , [위치])
--: 내림처리 (절삭) 함수(인자로 전달받은 숫자 혹은 컬럼의 지정한 위치 이후의 소수점 자리수를 버리는 함수 )
-- CEIL (숫자 | 숫자로된 컬럼명): 올림처리함수(소수점 기준으로 올림처리)
-- 날짜 함수 : SYSDATE, MONTHS_BETWEEN, ADD_MONTH
-- , NEXT_DAY, LAST_DAY, EXTRACT
-- SYSDATE : 시스템에 저장되어있는 날짜를 반환하는함수
-- MONTHS_BETWEEN(날짜, 날짜) : 두날짜의 개월수 차이를 숫자로 리턴하는 함수
-- ADD_MONTHS(날짜, 숫자): 날짜에 숫자만큼 개월수를 더해서 리턴
-- NEXT_DAY(기준날짜, 요일(문자|숫자)) :
-- 기준날짜에서 구하려는 요일에 가장가까운 날짜리턴

5 : 목요일
SYSDATE NEXT_DAY
22/07/26 22/07/28
--LAST_DAY(날짜 ) : 해당월의 마지막 날짜를 구하여 리턴

LAST_DAY(SYSDATE) LAST_DAY(200910)
22/07/31 20/09/30
-- EXTRACT : 년, 월,일 정보를 추출하여 리턴 하는 함수
-- EXTRACT(YEAR FROM 날짜) : 년도만 추출
-- EXTRACT(MONTH FROM 날짜) : 월만추출
-- EXTRACT(DAY FROM 날짜) : 날짜만 추출

출력 결과

★★★★★★★★★★★
--형변환 함수
--TO_CHAR(날짜, [포멧]) : 날짜형데이터를 문자형 데이터로 변환
--TO_CHAR(숫자, [포멧]) : 숫자형데이터를 문자형 데이터로 변환
--Format 예시 설명
--,(comma) 9,999 콤마 형식으로 변환
--.(period) 99.99 소수점 형식으로 변환
--0 09999 왼쪽에 0을 삽입
--$ $9999 $ 통화로 표시
--L L9999 Local 통화로 표시(한국의 경우 \)
--9:자릿수를 나타내며 ,자릿수가 많지않아도 0으로채우지않는다
--0:자릿수를나타내며, 자릿수가 많지 않을 경우 0으로 채워준다.
--EEEE 과학 지수 표기법


-- RR과 YY의 차이
-- RR은 두자리 년도를 네자리로 바꿀 때
-- 바꿀 년도가 50년 미만 2000년을 적용,
-- 50년 이상이면 1900년 적용
-- 년도 바꿀 때(TO_DATE 사용시) Y를 적용하면
-- 현재 세기(2000년)가 적용된다.
-- R은 50년 이상이면 이전 세기(1900년),
-- 50년 미만이면 현재 세기(2000년) 적용
-- * TO_CHAR 를 이용하여 뽑아오는것은 동일

출력 결과
YY

RR

-- 오늘 날짜에서 일만 출력


--NULL처리 함수
--NVL(컬럼 명, 컬럼 값이 NULL일 때 바꿀 값)
--NVL2(컬럼 명, 바꿀 값1, 바꿀 값2)
-- 해당 컬럼이 값이 있으면 바꿀 값 1로 변경
-- 해당 컬럼이 값이 NULL일 경우 바꿀 값 2로 변경
-- 선택함수 ★★★★★★★★★★★★
-- DECODE(계산식 | 컬럼명, 조건값1, 선택값1, 조건값2, 선택값2...,[DEFAULT])

주민등록번호 8번째 자리로부터 1글자를 잘라내서 (뒷자리 첫 번째 자리) 1이면 남자, 2면 여자를 리턴
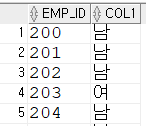

조건값 - 결과값 대응되는거 없는 맨 마지막 인자는 디폴트값이 된다
★★★★★★★★★★★★
-- CASE문
/* CASE
WHEN 조건식 THEN 결과값
WHEN 조건식 THEN 결과값
ELSE 결과값
END
*/


★★★★★★★★★★★
--그룹함수 : SUM, AVG, MAX, MIN, COUNT
-- SUM(숫자가 기록된 컬럼명 ): 합계를 구하여 리턴
-- AVG(숫자가 기록된 컬럼명): 평균을 구하여 리턴
-- MIN(컬럼명): 컬럼에서 가장 작은 값 리턴 (자료형 ANY TYPE)
-- MAX(컬럼명): 컬럼에서 가장 큰값 리턴 (자료형 ANY TYPE)
--COUNT(* |컬럼명 ): 행의 갯수를 리턴
--COUNT([DISTINCT] 컬러명):중복을 제거한 행 갯수 리턴
--COUNT(*) :NULL 을 포함한 전체 갯수 리턴
--COUNT(컬럼명): NULL 을 제외한 실제값이 기록된 행의 갯수 리턴
ㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡ
03_ ORDER BY , HAVING
/*ORDER BY 절: SELECT 한 컬럼을 가지고 정렬을 할때 사용함
ORDER BY 컬럼명| 컬럼별칭 | 컬럼나열 순번 [ASC] | DESC
ORDER BY 컬럼명 정렬방식, 컬럼명 정렬방식, 컬럼명 정렬방식.....
첫번째 기준으로 하는 컬럼에 대해서 정렬하고, 같은 값들에대해 두번째 기준으로 하는 컬럼에 대해 다시 정렬,
SELECT 구문 맨마지막에 위치하고, 실행순서도 맨 마지막에 실행됨.*/
/*
5 : SELECT 컬럼명 AS 별칭, 계산식, 함수식..
1 : FROM 참조할 테이블
2 : WHERE 컬럼명 | 함수식 비교연산자 비교값 (조건)
3 : GROUP BY 그룹으로 묶을 컬럼명
4 : HAVING 그룹함수식 비교연산자 비교값 ( 그룹핑된 대상에 대한 조건 )
6 : ORDER BY 컬럼명| 컬럼별칭 | 컬럼나열 순번 [ASC] | DESC |[NULLS FIRST | LAST]
*/
--GROUP BY 절 : 같은 값들이 여러개 기록된 컬럼을 가지고 하나의 그룹으로 묶음
--GROUP BY 컬럼명 | 함수식 ....
--GROUP BY 에 명시된 값 이 SELECT 절에 명시되어있어야한다.
--HAVING 절 : 그룹 함수로 구해올 그룹에 대해 조건을 설정할때 사용
--HAVING 컬럼명 | 함수식 | 비교연산자 |비교값
-- EMPLOYEE테이블에서 부서별 그룹의 급여 합계중 9백만원을 초과하는 부서코드와 급여합계를 조회


GROUP BY 만 했을 때

HAVING 으로 GROUP 에 대한 조건 설정을 했을 때

--집계함수
--ROLLUP 함수 : 그룹별로 중간 집계 처리를 하는 함수
--CUBE 함수 : 그룹별 산출한 결과를 집계하는 함수이다.
--GROUP BY 절에서만 사용
-- 그룹별로 묶여진 값에 중간집계와 총집계를 구할때 사용
-- 그룹별로 계산된 값에대한 총집계가 자동으로 추가된다.
-- 인자로 전달한 그룹중에서 가장 먼저 지정한 그룹(컬럼)별 합계와 총합계
--GROUPING 함수 : ROLLUP이나 CUBE 에 의한 산출물이
-- 인자로 전달받은 컬럼집합의 산출물이면 0
-- 아니면 1을 반환하는 함수


--@SET SPERATION(집합연산)
-- 두개이상의 테이블에서 조인을 사용하지않고 연관된 데이터를 조회하는 방법
-- 여러개의 질의 결과를 연결하여 하나로 결합하는 방식
-- 각테이블의 조회결과를 하나의 테이블에 합쳐서 반환함
-- 조건 : SELECT 절의 "컬럼수가 동일"해야함 ★★★★★★
-- SELECT 절의 동일 위치에 존재하는 "컬럼의 데이터 타입이 상호호환"가능해야함.
-- UNION, UNION ALL, INTERSECT, MINUS
-- UNION : 여러개의 쿼리결과를 하나로 합치는 연산자이다.
-- 중복된 영역의 제외하여 하나로 합친다.
-- UNION ALL : 여러개의 쿼리결과를 하나로 합치는 연산자
-- UNION 과의 차이점은 중복영역을 모두 포함시킨다.
--INTERSECT : 여러개의 SELECT 한 결과에서 공통된 부분만 결과로 추출
-- 수학에서 교집합과 비슷
--MINUS : 선행 SELECT 결과에서 다음 SELECT 결과와 겹치는 부분을 제외한 나머지 부분만추출
-- 수학에서 차집합과 비슷 하다
'더존 노션 필기 옮기기 > SQL' 카테고리의 다른 글
| MySQL 튜토리얼 (1) | 2022.12.07 |
|---|---|
| Oracle EMPLOYEE DDL DML (0) | 2022.11.22 |
| SQL 3일차 오라클 DB3 조인, 서브쿼리 (0) | 2022.08.30 |
| SQL 1일차 오라클DB 설치 및 설정 (0) | 2022.08.30 |